Screens, Research and Hypertext
Powered by 🌱Roam GardenURIs and URLs
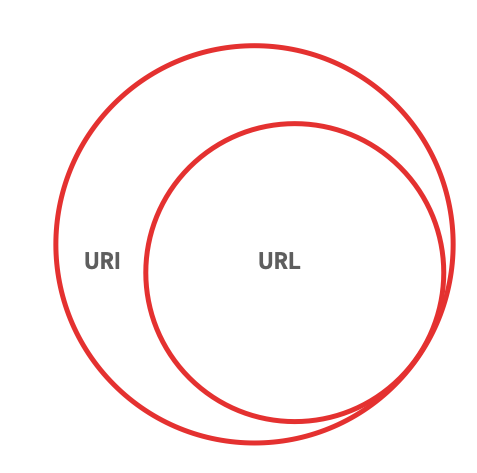
URI stands for Uniform Resource Identifier. A URI is a way of picking out a specific entity. The URI is how you pick out a specific thing, and how you distinguish that thing from different (if similar) things.
A URL, or Uniform Resource Locator, also picks out specific things, but it adds an additional piece of information—namely, a protocol used for accessing that information. The bit at the beginning of a URL—the https:// part—is the bit that explains that you access a particular thing using the HyperText Transfer Protocol Secure method of access.
A good way to think of the distinction is that all URLs are URIs, but not all URIs are URLs.
Referenced in
Transclusion and URLs
In most of the CMSs widely in use in the research sector, URIs don't work that way. Sure, your media files probably have unique URIs. But your text—along with all the other stuff on the page like sidebars and metadata—has just one URI.
Transclusion
When Sir Tim Berners-Lee built the three protocols that underlie the web—the hypertext transfer protocol (or http), the uniform resource locator (or URL) and a hypertext markup language (or HTML)—he prioritized linking between resources over embedding content. Indeed, in some ways, "linking between resources" overstates things. Properly speaking, HTML doesn't link resources so much as it provides an address where a relevant resource should be located. And even then, those links run in only one direction.
Version Control and Transclusion
When you embed a piece of content, you pull through whatever content exists at that URL. When you are fully in control of the content at both the source URL and the destination of the embed, that's not a problem. But when you embed a URL whose content you do not control, then things can get complicated.